Para algunos esto puede ser obvio, pero para quienes recién se introducen en Arquitectura de Información es una fuente de confusión constante: la estructura de contenidos no necesariamente es equivalente a la estructura de navegación de un sitio.
La estructura de contenidos o taxonomía de un sitio no tiene por qué, obligatoriamente verse fielmente reflejada en la estructura de navegación principal de un stio. De hecho, un sitio puede presentar múltiples formas de navegación, desde el clásico menú principal, pasando por menús contextuales, vínculos en el contenido, etc., hasta sistemas de búsqueda.
El objetivo de la taxonomía es organizar los contenidos de manera lógica utilizando diversos criterios. Esto permite ordenar los contenidos en un sistema estructurado, relacionado y eventualmente jerarquizado. Pero los modos que dispondremos para utilizar estos contenidos siguen patrones diferentes.
En el caso específico del patrón de menú de navegación principal se presentan secciones o categorías de contenido que se desea destacar, pero que pueden no corresponder exactamente a la misma estructura de clasificación de la taxonomía del sitio.
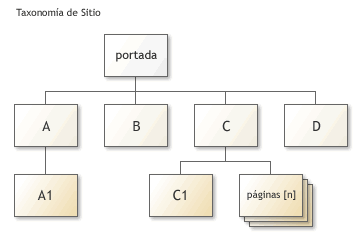
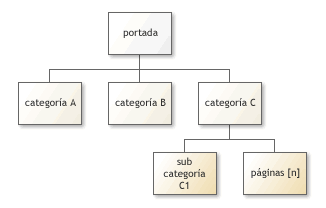
El diagrama muestra una estructura simple de contenidos en una relación jerárquica.
El diagrama anterior nos presenta una estructura de contenidos simple con subcategorías. No todas las categorías de primer nivel formarán parte del menú principal de navegación, sólo aquéllas que sea necesario destacar.

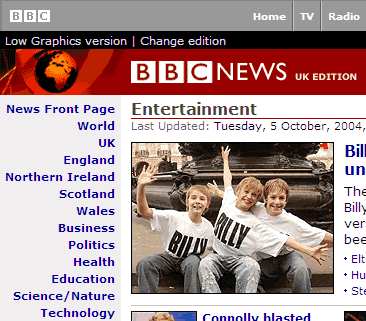
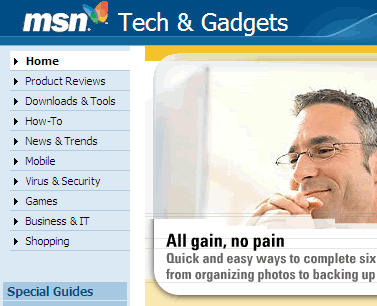
La ilustración muestra un esquema simple del patrón menú de navegación principal que utiliza algunas de las categorías representadas en el diagrama de contenidos anterior.
El esquema de navegación que presentamos arriba pretende ilustrar la situación que estoy tratando de exponer: la estructura de navegación utilizará algunas de las categorías de la taxonomía, pero no necesariamente todas y tampoco será necesario que pertenezcan al mismo nivel.
El criterio mediante el que seleccionaremos los contenidos de la navegación estará relacionado con el modo en que pretendemos guiar el recorrido de los contenidos, aquellos aspectos que necesitamos destacar particularmente. La taxonomía, en tanto, utilizará criterios de organización lógica.
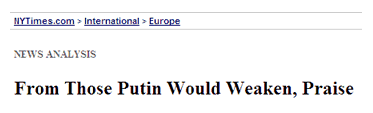
La taxonomía, en cambio, tendrá un rol relevante en el uso de otros mecanismos, como los motores de búsqueda y sistemas facetados de navegación, como catálogos de productos y directorios entre otros. Uno de los lugares en que más probablemente observemos la evidencia de la taxonomía de un sitio será en el uso de los menús de rastros, que representarán la jerarquía de los contenidos en forma descendente hasta la página actual.