Problema
Se necesita un sistema que permita orientar al usuario sobre la ubicación de la página que está leyendo en un sitio web, respecto a la estructura de contenidos global. Esta información debe estar disponible en el contexto de la propia página, por lo que el mapa del sitio no soluciona el problema.
Por qué
Normalmente la estructura de navegación de un sitio no otorga información suficiente que permita ubicar precisamente una página dentro del contexto global de los contenidos de un sitio. Cuando el sitio tiene una estructura de contenidos compuesta de múltiples niveles resulta difícil reconocer la ubicación de las páginas interiores respecto a la arquitectura de información del sitio. Este problema se hace más evidente cuando un usuario ingresa al sitio desde páginas interiores, por ejemplo mediante un vínculo en una página de resultados en un buscador, pero es igualmente relevante para los usuarios que navegan el sitio de modo convencional.
Cuándo
Cuando la estructura de contenidos de un sitio presenta una profundidad mayor a dos niveles y resulta necesario entregar un refuerzo sobre la ubicación de la página respecto a la estructura de contenidos del sitio.
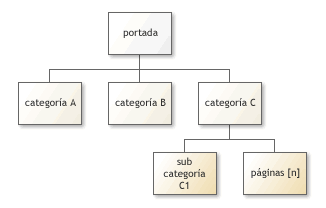
El diagrama de arquitectura de información simplificado muestra una estructura de contenidos de varios nieveles de profundidad.
Solución
Proveer un sistema jerarquizado de vínculos a las secciones o páginas padre desde la página actual hasta la portada. El sistema debe:
- Representar claramente la jerarquía descendente hasta la página
- Utilizar un elemento separador que refuerce esa jerarquía entre cada vínculo
- Estar orientado de izquierda a derecha y en la parte superior de la página, normalmente bajo el encabezado de la página y sobre los contenidos.
Ocasionalmente se observa el uso de textos como Usted está en:
para reforzar la funcionalidad ubicación de este elemento.

El diagrama muestra la ubicación común de los menús de rastros en una página.
Ejemplos
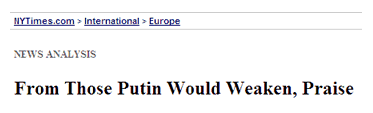
Ejemplo de menú de rastros en NYTimes.com.

Ejemplo de menú de rastros en PCWorld.com.

Ejemplo de menú de rastros en Reuters.com.
Observaciones
Es preciso hacer notar que el nombre en inglés, breadcrumbs así como la traducción de menú de rastros resulta confuso, dado que el objetivo de este patrón no es informar sobre la ruta de navegación que ha seguido el usuario para llegar a la página en cuestión, sino que informar sobre la ubicación de la página en el contexto de la estructura de contenidos del sitio.
Esto último incluso nos lleva un poco más lejos: en un sitio con una cantidad importante de contenidos, la arquitectura de información no necesariamente reflejará la estructura de navegación. La clasificación de los contenidos puede generar una estructura que no se refleje fielmente en el menú de navegación, por cuanto éste estará compuesto por categorías de navegación que idealmente contendrá accesos directo a zonas de interés específico en el sitio. La decisión entonces es ¿usar categorías de navegación o la clasificación de los contenidos del sitio? Creo que se debería utilizar la clasificación de contenidos del sitio, así como en el mapa del sitio.
Cabe también citar el ejemplo que presenta Jesús Carreras del uso para representar navegación en Tipos de Breadcrumbs, o cómo orientar al usuario, aunque personalmente no estoy consciente de haber encontrado otros ejemplos similares.
Referencias
- http://www.welie.com/patterns/showPattern.php?patternID=crumbs
- http://www.visiblearea.com/cgi-bin/twiki/view/Patterns/Homeward_path
- Tipos de Breadcrumbs, o cómo orientar al usuario
Los logos y marcas que aparecen en esta página son propiedad de sus respectivos dueños. Las capturas de pantalla de sitios de terceros se presentan para efectos ilustrativos y no representan vinculación, aprobación ni otro tipo de relación.
