El concepto de web semántica no es nada nuevo, de hecho es tan antiguo como la propia web. Ya en las primeras versiones de HTML (1993), se definen elementos semánticos que permiten establecer relaciones entre recursos o documentos, —el elemento link con el atributo rel, por ejemplo—, así como elementos estructurales que permiten definir una jerarquía interna a cada documento HTML —como los títulos h1 a h6.
Todos sabemos lo que ocurrió luego, en los primeros años de la web: la irrupción masiva de Internet con la guerra de los browsers, nos llevó a la pérdida de muchos de los principios semánticos. Pero la idea siempre ha estado presente.
En 2001 Tim Berners-Lee publicó The Semantic Web, planteando la necesidad de otorgarle una estructura semántica al contenido de la web, que facilitara la relación entre el contenido y mejorara el funcionamiento de los buscadores. La visión de una nueva forma de contenido web, que es significativa para los computadores, liberará una revolución de nuevas posibilidades
, pero su despliegue ha tardado en producir suficiente tracción.
En el camino surgieron iniciativas como microformatos, que ante la falta de estándares semánticos, buscaban agregar una capa de significado directo en HTML. Aunque tuvo bastante aceptación en ciertos círculos, nunca tuvo un uso predominante.
Pero la necesidad de darle significado al contenido sigue presente. El problema de fondo es el incentivo: ¿Cuál es el beneficio directo de describir semánticamente contenido para quienes producen esa información? ¿Quién será capaz de valorizar el contenido, su significado y sus relaciones? En otras palabras: ¿Cómo gano con esto?
Pues bien, en el momento en que los grandes actores del mudo del web comienzan a valorar el contenido estructurado y descrito semánticamente, el beneficio potencial comienza a hacerse concreto. Me refiero a Google, Microsoft, Yahoo y Yandex, con el proyecto Schema.org.
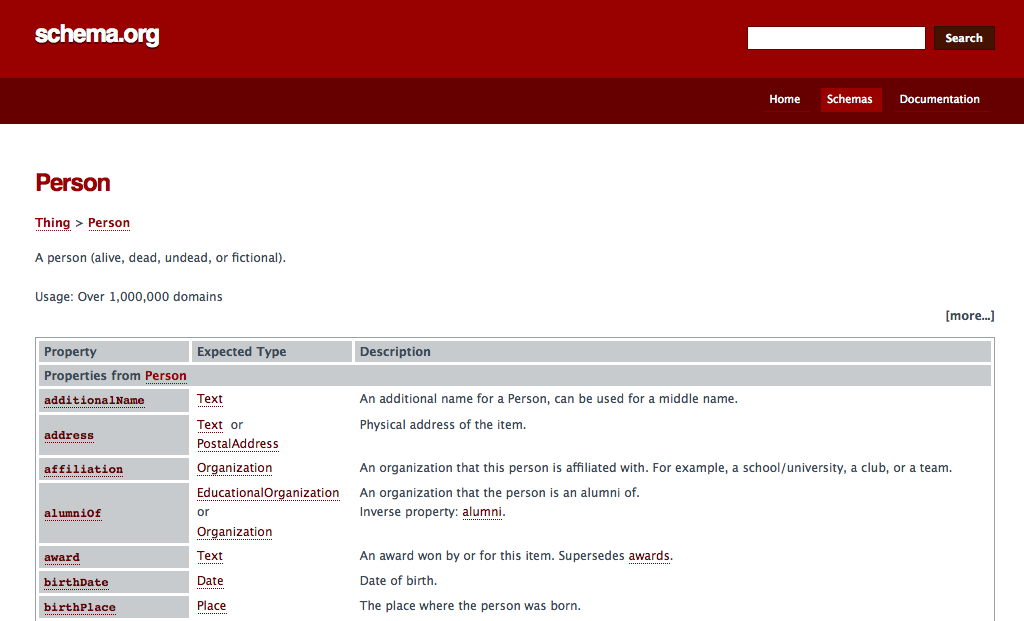
Schema.org es un esfuerzo conjunto para generar ontologías de diversos espacios de conocimiento —aunque las llaman esquemas o vocabularios—, que permite a los productores o publicadores de contenido describirlo de modo que los buscadores —en primera instancia— puedan identificarlo con precisión. Esto es precisamente a lo que se refería Berners-Lee en su escrito del 2001.
Lo que busca un proyecto como Schema.org es precisamente producir ese beneficio directo: mayor precisión en las búsquedas, es decir, mejor posicionamiento y relevancia. Gana el buscador entregando un mejor servicio, el usuario al obtener mejores resultados y los publicadores de contenido o servicios al ser encontrados con mayor facilidad.
Las ontologías de Schema.org incluyen un conjunto de vocabularios para tipos como Eventos, Organizaciones, Personas, Productos, etc., que pueden ser integrados al HTML de un sitio mediante microformatos, RDFa o JSON. El conjunto de esquemas está en crecimiento y hay colaboración de múltiples participantes, en lo que parece ser un proyecto saludable.
Lo dejo hasta acá por ahora, si aún no lo conocen, den una mirada a Schema.org.
