Un problema frecuente en las aplicaciones web abiertas al público es el de los scripts automatizados que tratan de explotar algunas de sus caraterísticas para propósitos diversos, normalmente ilegítimos. Desde los robots que ingresan comentarios spam a los blogs por miles, hasta aquéllos que intentan abusar de los servicios de correo como MSN, Yahoo! y más recientemente Gmail, el factor común es que se trata de scripts o programas relativamente pequeños que se diseñan para abusar específicamente de ciertos sistemas.
Los spammers de blogs apuntan en particular a los comentarios, normalmente abiertos al público, para dejar vínculos que pretenden sacar partido de los buscadores que valoran positivamente la cantidad de referencias a un sitio. Los wikis, con su esencial característica de edición colectiva, son vulnerables también a estos problemas.
Una forma específica de enfrentar el problema, es utilizar un mecanismo que permita garantizar que quien realiza una acción es un humano y no un robot programado. La técnica más común es el uso de imágenes distorsionadas que para los humanos resultan relativamente simples de leer, pero que para un programa es muy difícil procesar. Estas imágenes son conocidas como captchas.
Captchas

Ejemplo de una imagen captcha (imagen de dominio público, publicada en Wikipedia).
Partamos por la definición del nombre: éste es una abreviación de Completely Automated Public Turing Tests to Tell Computers and Humans Apart
, algo así como Prueba Turing Pública Completamente Automatizada para Diferenciar Humanos y Máquinas
y fue acuñada por un equipo de IBM en el año 2000.
Esta técnica, desarrollada originalmente por AltaVista en 1997, busca distinguir claramente a un humano de un proceso programático, mediante el uso de imágenes distorsionadas de un modo que haga imposible el que sean leídas por algo que no sea un humano. Quien esté familiarizado con los escáneres de imágenes, probablemente conocerá también la tecnologíaOCR, Optical Character Recognition, que permite escanear páginas de texto como imágenes y transformarlas a texto. La tecnología OCR permite reconocer caracteres desde imágenes mediante análisis de inteligencia artificial, y demuestra que si bien se puede programar un sitema para que reconozca imágenes, deben existir ciertas condiciones para que el reconocimiento de los caracteres sea más fácil. Por lo mismo, los captchas distorsionan la imagen de un modo que hace imposible que que las tecnologías OCR actuales identifiquen su significado. Algunas de las técnicas para ocultar el texto en la imagen son el uso de tipografías poco usuales, distorsionadas, irregulares, junto con diferentes colores y elementos de ruido visual. Vale hacer notar que con un esfuerzo considerable es posible programar sisteas que sean capaces de leer captchas, pero normalmente el costo de esto es muy alto.
La técnica completa de los captchas consiste en presentar una imagen al usuario y solicitarle que ingrese el texto que reconoce en ella en un campo, normalmente una mezcla de caracteres alfanuméricos, y luego se comparan ambos para verificar si coinciden. Un script automátizado no pasará la prueba, en tanto un humano sí. ¿Sí?
Accesibilidad y Captcha
La base de la técnica de captcha se basa en que los humanos podemos leer. Pues bien, la mayoría lo hace, pero no todos podemos leer. Sí, me refiero a los ciegos. Esto establece un problema de accesibilidad concreto, que de no ser corregido, significa discriminación. La buena noticia, es que los captchas no sólo se pueden realizar con imágenes, es posible también utilizar audio para entregar información que sólo será diferenciable para humanos. La técnica es similar: se presenta la grabación de una serie aleatoria de letras y números en con ruido auditivo y cierta distorsión. Lo ideal es tener ambos sistemas, captcha de imagen y de audio, para permitir que todos los usuarios puedan ciertamente pasar la prueba de discriminación de humanos y máquinas.
En el Mundo Real
En muchos casos he encontrado captchas de imagen en sitios públicos como Yahoo! o incluso más recientemente en Gmail. Pero en todos los casos se omitía el problema de accesibilidad. En Gmail parecen tener planes al respecto, porque junto a cada imagen captcha se encuentra un gráfico pequeño con el símbolo de discapacidad, aunque la solución ofrecida es actualmente bastante pobre: abre una ventana nueva usando JavaScript, la ventana tiene el mismo captcha con texto en el atributo ALT que dice algo como usted no puede ver la imagen porque las tiene desactivadas en el navegado. Cómico, si lo quieres tomar con humor.
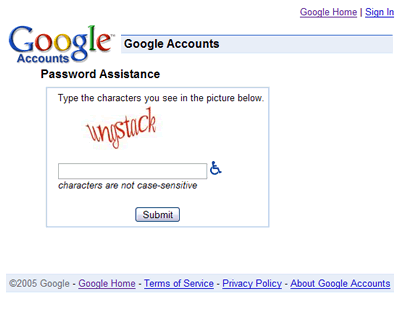
Gmail utiliza captchas en su proceso de recuperación de claves perdidas.

El registro de nuevos usuarios de Yahoo! hace uso de captchas.
Sin embargo, hace uns días me llevé una sorpresa, que fue la que me motivó a escribir este ya extenso post: en MSN utilizan captchas de imagen y audio. Las siguientes imágenes muestran parte del proceso de creación de nueva cuenta y al final hay un ejemplo del captcha de audio.
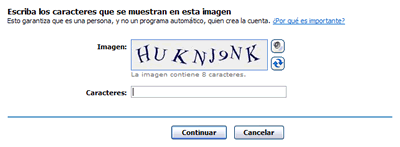
MSN utiliza captchas en el proceso de creación de nuevas cuentas de usuarios. A la derecha del captcha de imagen, se pude observar un ícono de sonido, que permite acceder a un captcha de audio para aquellos usuarios que lo necesiten.
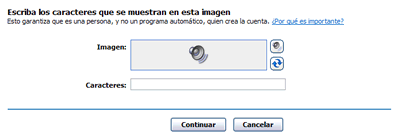
Al seleccionar el ícono de audio, MSN presenta un botón que permite oir un captcha sonoro.
El captcha de audio presentado por MSN es una lectura distorsionada de una serie de números que se oye así (WAV, 64Kb.). Vale hacer notar también que la grabación del captcha se presenta en castellano, como corresponde a un sitio mulilingüe.
Nota: El audio se presenta sólo para efectos ilustrativos, y cumplo con señalar que es de propiedad de MSN.
Más Información
Si el tema te interesa, te recomiendo algunos lugares para buscar más información sobrecaptchas:
- Proyecto Captcha del Palo Alto Research Center
- Información en Wikipedia
- Proyecto Captcha, Carnegie Mellon University
- Una nota del W3C sobre los problemas de accesibilidad de los captchas
- Wikipedia hace notar la vigencia de una patente en EE.UU. que cubre el concepto

{kind=link}